Chinese Web Sites Using PHP - v2.24, by Herong Yang
Restore Corrupted Chinese Text
This section provides a tutorial example to restore corrupted Chinese text with different suggested solutions.
How to restore corrupted Chinese text? This no single solution that can be applied to all situations of corrupted Chinese text. As you can see from previous tutorials, the original Chinese text could be stored in 3 or more encodings. The next system could mistakenly decoded with one of many possible 8-bit encodings. The situation could get even worse, if the corrupted Chinese text get decoded again by a third system with another 8-bit encoding.
However, I have suggestions that could help you to restore corrupted Chinese text.
1. Backup a copy the corrupted Chinese text from further corruption by converting it into hexadecimal format.
2. Determine the current encoding of the corrupted Chinese text. This can be done by reviewing its binary strings. And also assume that a large number of Chinese systems use GB18030 (GBK) encoding. Most of other systems use UTF-8. Assume that the current encoding is EncodingY.
3. Determine the encoding used by the last system to decode the original Chinese text. This is the most difficult step. You need to review those strange characters displayed from the corrected Chinese text. And try to map them to a guessed 8-bit encoding table. Assume that the guessed encoding the corrupted Chinese text was decoded from is EncodingX.
4. Try to convert corrupted Chinese text to the original Chinese text by calling a conversion tool like "iconv" on a Linux system.
iconv -f EncodingY -t EncodingX corrupted_text > recovered_text
5. Display "recovered_text" as UTF-8, UTF-16BE, or GB18030. If it is showing as valid Chinese text. Job is done. Otherwise go back to step 3.
Let's apply those suggestions on the corrupted file name coming out from a ZIP file on my macOS computer.
1. Backup a copy the corrupted Chinese text into a hexadecimal format using "xxd corrupted.txt > corrupted.hex" command as shown in the picture below.
2. Determine the current encoding of the corrupted Chinese text by looking that the binary data. Since I am using a macOS computer, my first guess is UTF-8. To confirm this, I take the first 3 bytes from the binary data: 0x'e28891', and searches on the Internet. It is a valid 3-byte sequence of UTF-8 encoding. So EncodingY = UTF-8.
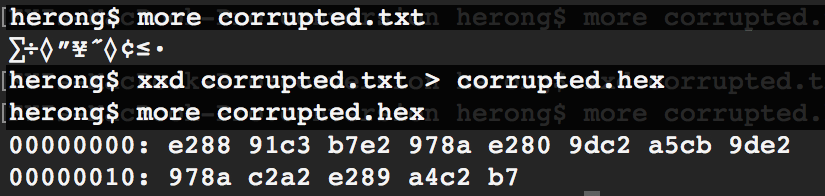
3. Determine the encoding used by the last system to decode the original Chinese text, by looking at those junk characters displayed from the corrupted text. The ISO-8859-1 table has the Japanese Yen sign, but not the upper Sigma letter. The CP437 encoding table has the upper Sigma letter, but not the diamond sign. Since I am using a macOS computer, let's see the MAC encoding table by running "php 8-Bit-Encoding-Table.php MAC" as shown below. Luckily, the MAC encoding table has all those junk characters. So let's set EncodingX = MAC.

4. Try to convert corrupted Chinese text to the original Chinese text by calling "iconv" command:
herong$ iconv -f UTF-8 -t MAC corrupted.txt > recovered.txt herong$ xxd recovered.txt 00000000: b7d6 d7d3 b4fd d7a2 b2e1 ..........
5. Display the recovered text as a Chinese encoding. By looking at the binary string of the recovered text, it seems to be GB18030 encoding. Let's try to display it using "iconv -f GB18030 -t UTF-8 recovered.txt | more" command.

And it works! I am able to recover the corrupted Chinese file name created by macOS auto unzip tool from a ZIP archive.
Table of Contents
PHP Installation on Windows Systems
Integrating PHP with Apache Web Server
charset="*" - Encodings on Chinese Web Pages
Chinese Characters in PHP String Literals
Multibyte String Functions in UTF-8 Encoding
Input Text Data from Web Forms
Input Chinese Text Data from Web Forms
MySQL - Installation on Windows
MySQL - Connecting PHP to Database
MySQL - Character Set and Encoding
MySQL - Sending Non-ASCII Text to MySQL
Retrieving Chinese Text from Database to Web Pages
Input Chinese Text Data to MySQL Database
►Chinese Text Encoding Conversion and Corruptions
Detect System Default Encoding
Root Cause of Corrupted Chinese Text
Corrupted Chinese File Name with Un-ZIP
Generate 8-Bit Encoding Tables
►Restore Corrupted Chinese Text