Chinese Web Sites Using PHP - v2.24, by Herong Yang
Corrupted Chinese File Name with Un-ZIP
This section provides a tutorial example to demonstrate a real life example of Chinese text corruption when unzip ZIP archives generated from Chinese Windows systems.
Here is a real life example of Chinese text corruption I have experienced with ZIP archives.
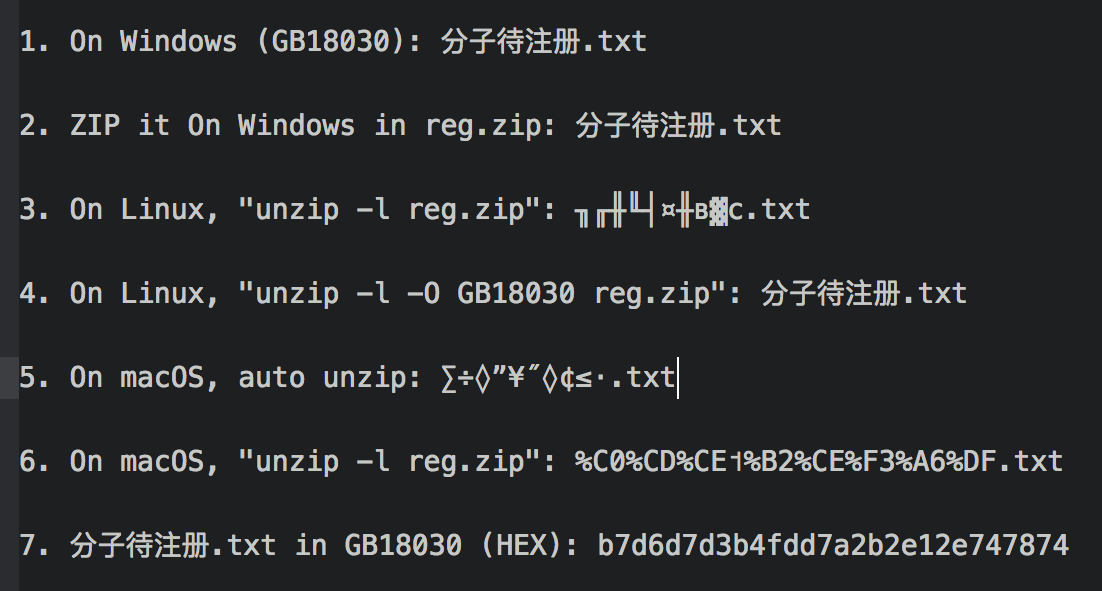
1. The original file is encoded as GB18030 (GBK) on a Chinese Windows system.
2. The file gets zipped on Windows as reg.zip. with GB18030 encoding maintained.
3. When open reg.zip with "unzip" using default options on Linux, I see corrupted Chinese text as shown at line #3 in the following picture.
4. When open reg.zip with "unzip" using "-O GB18030" option on Linux, I see correct Chinese text as shown at line #4 in the following picture.
5. When reg.zip is automatically unzipped by macOS, I see corrupted Chinese text as shown at line #5 in the following picture.
6. When open reg.zip "unzip" on on macOS, I see corrupted Chinese text as shown at line #6 in the following picture.
7. To help troubleshooting the problem, I generated the binary code (in Hex format) of the original file name in GB18030 encoding: b7d6d7d3b4fdd7a2b2e12e747874.
As you can see, the problem of corrupted Chinese text in this case is really caused by different systems using incorrect encodings to decode the file name in the ZIP archive. The file name was correctly stored in the ZIP archive. This is approved by step #4.
So the solution is simple in this case, we need to tell the Un-ZIP tool what is the original encoding used in the ZIP archive. This can be done easily on a Linux system with the "unzip -O xxx" option. But that option is not support on my macOS computer. So I need to upgrade the "unzip" tool, or find a new tool.
If you are curious about the default encodings used by macOS and Linux that generated corrupted Chinese file names from the ZIP archive, you need to decode each corrupted Chinese text set by comparing it with different 8-bit encoding tables to find out the encoding.
For example, the corrupted Chinese file name generated from the "unzip" default option on Linux looks like a good match to the CP437 code page with those box drawing characters. So Linux might be using CP437 as the default encoding with the "unzip" tool.
By the way, this corrupted Chinese file name issue is very common, if you receive a ZIP file from a Chinese Windows system. So try to unzip it with GB18030 as the encoding.
Table of Contents
PHP Installation on Windows Systems
Integrating PHP with Apache Web Server
charset="*" - Encodings on Chinese Web Pages
Chinese Characters in PHP String Literals
Multibyte String Functions in UTF-8 Encoding
Input Text Data from Web Forms
Input Chinese Text Data from Web Forms
MySQL - Installation on Windows
MySQL - Connecting PHP to Database
MySQL - Character Set and Encoding
MySQL - Sending Non-ASCII Text to MySQL
Retrieving Chinese Text from Database to Web Pages
Input Chinese Text Data to MySQL Database
►Chinese Text Encoding Conversion and Corruptions
Detect System Default Encoding
Root Cause of Corrupted Chinese Text
►Corrupted Chinese File Name with Un-ZIP
Generate 8-Bit Encoding Tables
Restore Corrupted Chinese Text