Unicode Tutorials - Herong's Tutorial Examples - v5.32, by Herong Yang
EUC-JP Encoding
This section provides a quick introduction of EUC-JP encoding, which maps a JIS X0208 character to a 2-byte sequence by adding 128 (0x80) to both bytes of the character's code value.
EUC-JP (Extended Unix Code for Japanese): An encoding for JIS X0208 character set. It is an 8-bit encoding with 1 or 2 bytes per character:
Number Of Valid Range Bytes Byte 1 Byte 2 1 0x21 - 0x7F 2 0xA1 - 0xFE 0xA1 - 0xFE
Of course, 1-byte encoding sequences are used for ASCII characters.
2-byte encoding sequences are used for JIS X0208 characters. The mapping schema is simple. The first byte of a encoding sequence is the high byte value of the character code value plus 128 (0x80). The second byte of a encoding sequence is the low byte value of the character code value plus 128 (0x80).
In another word, EUC-JP encoding maps a JIS X0208 character to a 2-byte sequence with both byte values in the range of from 0xA1 to 0xFE, as shown in the picture below:
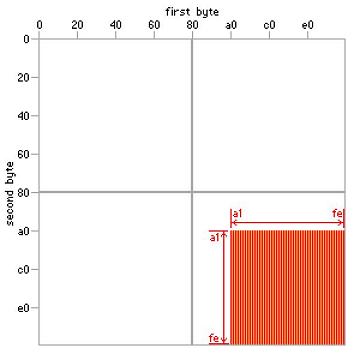
The advantage of EUC-JP encoding is that ASCII characters and JIS X0208 characters can be mixed together without using any escape sequences.
The disadvantage of EUC-JP encoding is that it uses 8-bit bytes, which are not safe to transmit through many communication interfaces.
Table of Contents
ASCII Character Set and Encoding
GB2312 Character Set and Encoding
GB18030 Character Set and Encoding
►JIS X0208 Character Set and Encodings
JIS X0208 Character Set for Japanese Characters
JIS X0208 Character Code Values
UTF-8 (Unicode Transformation Format - 8-Bit)
UTF-16, UTF-16BE and UTF-16LE Encodings
UTF-32, UTF-32BE and UTF-32LE Encodings
Python Language and Unicode Characters
Java Language and Unicode Characters
Encoding Conversion Programs for Encoded Text Files
Using Notepad as a Unicode Text Editor
Using Microsoft Word as a Unicode Text Editor